Amdahl’s Law
If we improve only one aspect of a computer system, the overall improvement in performance is limited by the extent the improved aspect is used. Amdahl’s Law addresses this limitation.
The law was presented by Gene Amdahl in 1967. Amdahl’s paper focuses on the potential speedup that can be expected by using multiple processors. The law can be generalized to assess other areas of performance as well. For example, we can asses improvements in floating point performance, memory, etc.
The first step in Amdahl’s Law is the categorization of code in a program as inherently serial and infinitely parallelizable. Let us say the fraction of the code which can be parallelized is f and the fraction of serial code is s. The formula for the serial code is \(s=1−f\), since \(s + f = 1\).
The main idea behind Amdahl’s Law is that as the number of processors increases, the time taken for executing f shrinks and becomes insignificant. After this point, the serial portion of the code starts to dominate execution times. Any further increase in the number of processors does not bring noticeable benefits.
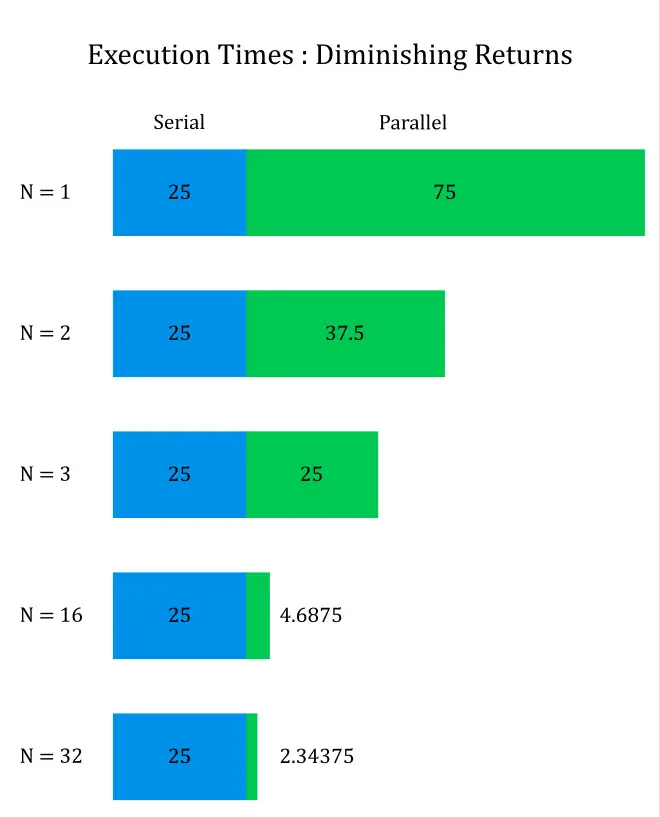
This limitation would not be an issue if we were looking for only small improvements in performance. But we often look at parallel processing as the magic bullet for processor performance. Let us look at an example. Assume that 75% of the execution time in a program is parallelizable; so the serial execution time is 25%. In this example, no matter how many processors we use, we cannot get more than a 4 times performance boost. The performance improvement hits a limit a lot quicker than most people imagine.
Formula
Let us look at the formula for calculating speedup. The speedup that can be expected from parallelism can be calculated as follows:-
$$\frac{Execution \: time \: on \: a \: single \: processor}{Execution \: time \: on \: multiple \: processors}$$It can also be calculated using:-
$$\frac{Performance \: after \: enhancement}{Performance \: before \: enhancement}$$The following expansion of the first formula is quite popular:-
$$ \begin{align*} Speedup &= \frac{T}{T(1-f)+\frac{Tf}{N}}\\ & = \frac{1}{(1-f)+\frac{f}{N}} \end{align*}$$Where T is the execution time on a single processor, f is the fraction of code which can be parallelized and N is the number of processors. Here \(T(1-f)\) refers to the execution time of serial code. It does not change depending on the number of processors. While \(\frac{Tf}{N}\) referes to the execution time of the parallel portion of the code; hence the division by N.
The last equation clearly shows that as N becomes large the term \(\frac{f}{N}\) becomes immaterial. After that point speedup flattens out.
Graphical Representation
The following graph should give a clearer picture of the limits of speedup for various values of f.
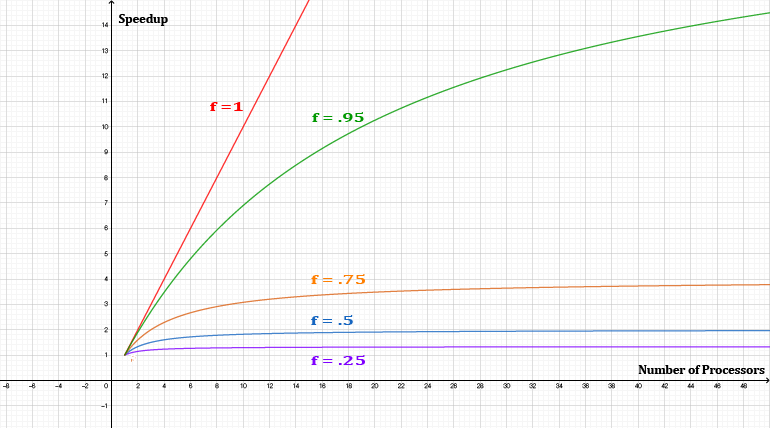
With f at 1, we get a perfect speedup. The speedup is quite impressive for f = .95 as well.